Haskell Database Implementation - Part 3, Indexes and Performance
This post is part 3 in a series on database implementation, part 2 is here.
In the last post I wrote about the DSL and transactions. This post is about indexes and performance.
If you’d like to skip ahead and read the code, it’s here.
Indexes
As I discussed in previous posts, one of the main reasons I wanted to implement a database from scratch was to learn about indexes. I don’t claim anything about my implementation as being “good” or “the best”, especially given that my design decisions allowed me to keep everything in memory, but this exercise helped me conceptualize how databases might store and maintain indexes.
Here’s a partial repost of the types from the previous post.
newtype IndexName = IndexName { unIndexName :: Text }
data Table = Table
...
, _tableIndices :: [IndexName]
}
data Index = Index
{ _indexName :: IndexName
, _indexTable :: TableName
, _indexColumns :: [ColumnName]
, _indexData :: TreeMap [Atom] [Row]
}
data Database = Database
{ _databaseTables :: Map TableName Table
, _databaseIndices :: Map IndexName Index
}
Table definitions are stored internally with references to index names. An index is stored with a reference to the table name, the column names in order they were specified, and the indexed data in a tree map (columns in the order they were specified).
I am unsure of how relational databases typically store compound indexes. One possibility is what I laid out, which is to simply store all of the data adjacently. Another possibility would be to deduplicate data in the first column of the compound index, and recursively nest the remaining columns under trees. It could depend on the shape of the data in the table (if duplicates in the first column are common), or perhaps the query planner and database statistics could help the database internally restructure the index over time, or something else entirely. I suppose this is part of the reason why databases are so great, and why I undertook this project. As with most of my other decisions, this was made purely out of simplicity’s sake.
The work done in the previous two posts helped make index construction and maintenance trivial. Having implemented the
TreeMap type and autocommit transactions, all I needed to do to create an index was traverse the table data,
restructure the tree by replacing the primary key with the index columns, and refresh the tree given the new keys.
execute :: MonadDatabase m => Statement -> m Output
execute = \ case
...
StatementCreateIndex indexName tableName cols -> do
-- fetch the table
table <- use (_1 . databaseTables . at tableName) >>= \ case
Nothing -> throwError $ StatementFailureCodeSyntaxError "Table does not exist"
Just t -> pure t
-- error if any columns specified in the index don't exist in the table
let extraColumns =
intercalate ", " . map unColumnName . setToList . difference (setFromList cols)
. asSet . setFromList . toListOf (tableDefinition . each . columnDefinitionName)
$ table
unless (null extraColumns) $ throwError $ StatementFailureCodeSyntaxError $ "Columns " <> extraColumns <> " not in table"
-- add the index to the table
modifying (_1 . databaseTables . at tableName . _Just)
( over tableIndices (indexName:)
)
-- create the index, failing if it already exists
use (_1 . databaseIndices . at indexName) >>= \ case
Nothing -> do
columnIndices <- getColumnIndices table cols
let contents = mapFromListWith (<>)
. map (\ (_, row@(Row atoms)) -> (map ((!!) atoms) columnIndices, [row]))
. mapToList
. view tableRows
$ table
modifying (_1 . databaseIndices) (insertMap indexName $ Index indexName tableName cols contents)
pure $ Output "CREATE INDEX"
Just _ -> throwError $ StatementFailureCodeSyntaxError "Index already exists"
As one might imagine, maintaining the index is pretty simple as it’s just an insert to the self-balancing TreeMap
using the columns specified in the index. I won’t go into that code in this post.
The query planner code is also simple in this case. If the where clause contains the same columns as an index on the table, use that index; otherwise, table scan.
select :: MonadDatabase m
=> Table -> [ColumnName] -> [WhereClause]
-> m [[Atom]]
select table cols wheres = do
let whereColumns = toListOf (each . whereClauseColumn) wheres
tableIndexMay <- headMay . filter ((==) whereColumns . view indexColumns) <$> getTableIndices table
maybe (selectTableScan table cols wheres) (\ index -> selectIndex table index cols wheres) tableIndexMay
Performance
Having created an index using the TreeMap type, I was pretty confident that using the index would be faster than using
a table scan. I wanted to know by how much, using a baseline of looking up by the primary key, so I wrote a benchmark
using the criterion package. I generated randomized data and, using pools of 10k, 100k, and 200k rows, selected by
primary key, with an index, and with a table scan. I won’t go into the benchmark code, but if you’d like to take a look
for yourself, it’s here.
Results
The results were pleasantly uninteresting, for someone who didn’t know what they were doing. The primary key lookup was the fastest, followed closely by the index. The table scan was far behind.
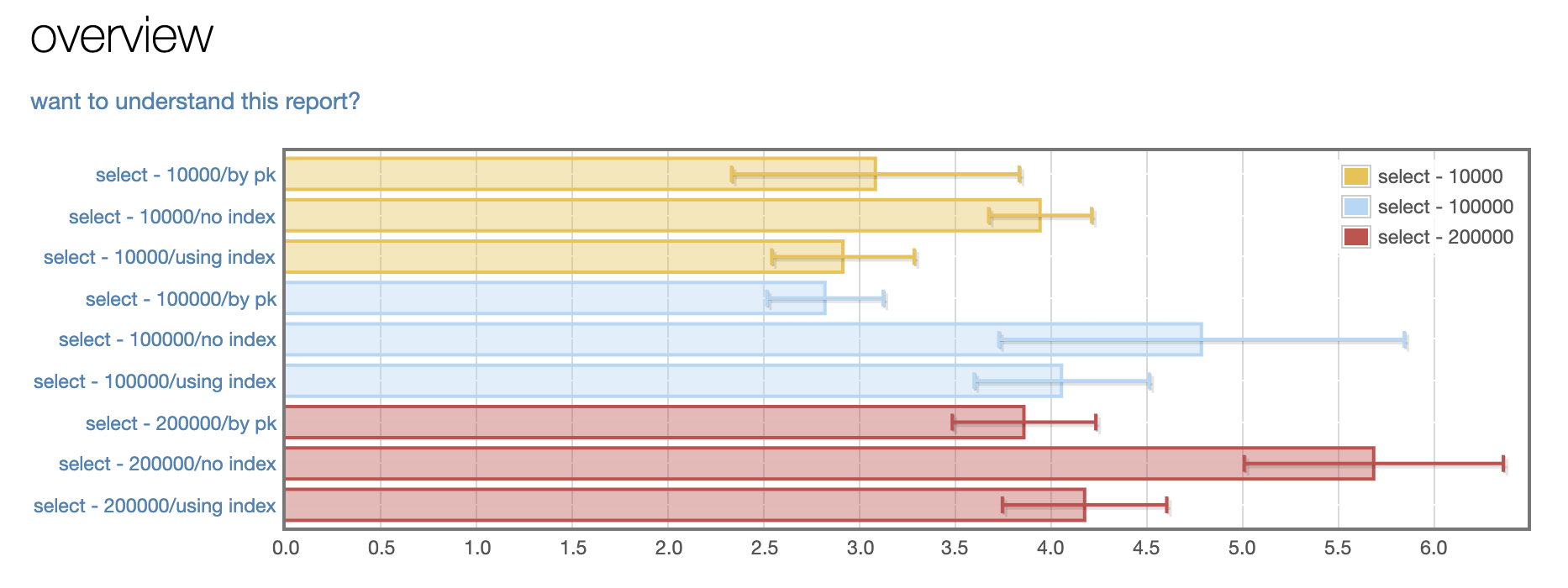
Notes on results
- I didn’t test with a compound index, though I imagine it would be slightly slower than an index with only one column due to the size of the index.
- Since the data for the benchmark was generated randomly, it doesn’t conform to real-world semantics. As such, the benchmark is largely testing the performance of binary search as opposed to how a real index might work. This might be more apparent if there were different index strategies (say, ranges or indexes on binary data), but as noted in part 2, the query language is very limited.
If you’d like to see the entirety of the benchmark results, they’re on GitHub.
Conclusion
Thanks for reading! It was really fun to learn about databases this way, and to be able to share all the things I learned.
As always, I’d love to hear anything I’ve mixed up, especially in this case from database experts. Find me on fpchat
(@dfithian) or reddit (/u/dfith).